How AI Optimization Drives Real Production Increases
Every production uplift number eventually has to be defended in a room full of engineers. The questions are always the same. What is the model actually doing. What physics is it grounded in. How is it making decisions. This article walks through how AI optimization actually produces the uplift numbers we see in deployment: where setpoint optimization recovers production on plunger and gas lift wells, how pad-level pressure interactions reshape every well's operating point at once, why multiple specialized models outperform any single monolithic one, how physics-based aids in the context, how signal pattern search is the pillar of reality, and what separates physics-based, ML-based, and AI optimization in practice.
An AI optimization recommendation comes out of four input categories working together. Statistical ML models surface the patterns. Physics constrains the answer to what is actually feasible at the wellbore. AI signal pattern matching grounds the model in what the time series is actually doing, well by well, cycle by cycle. AI context ties the recommendation to the specific state of the specific well: what was changed, what was it derived off of, what is moving on the pad around it. None of these inputs is sufficient alone. The output is various weights across these pillars.
One framing point first. There is always room for optimization on a producing well, but the limiter is not always the setpoint. Sometimes it is a mechanical signature, sometimes line pressure, sometimes a downstream issue. With Build Your Own Model the detectable signatures extend well beyond setpoint tuning: arrival switch issues, scale build-up in tubing, gas lift valves hung open, heated separator burner failures, dump valve failures, failing compressor valves, and more. Treating all of these as setpoint problems is exactly the failure mode this article is about.
Setpoint optimization: plunger lift
Plunger well optimization is not just a setpoint problem. The engineer is tuning afterflow timer, close pressure, open pressure, fast and slow trigger logic, and load factor, but those setpoints sit inside a larger system. Line pressure shifts. The lubricator wears, the bumper spring fatigues, the arrival switch develops contact issues. The controller runs the same logic against new physics and new equipment state until somebody intervenes. Good optimization has to read all of it, not just the setpoint side.
The cycle itself is governed by delta-P. The gas pressure built up below the plunger during the close period has to exceed the weight of the plunger, the weight of the liquid slug above it, and the line pressure the slug has to push into. If the delta-P is too low, the plunger stalls. If the delta-P is too high, the well opens with more pressure than necessary and the close period was longer than it needed to be. The whole optimization problem on a plunger well is finding the close pressure that produces just enough delta-P to lift the slug at the line pressure the well is currently flowing against.
Critical velocity is a separate question on plunger wells. It does not govern the cycle; it governs whether the well is unloading gas fast enough during afterflow to keep liquid from building up before the next cycle. It is most useful as a close trigger, telling the controller to shut in when flow drops below the rate required to keep the wellbore unloaded.
σ = surface tension (dynes/cm)
ρl = liquid density (lb/ft3)
ρg = gas density (lb/ft3)
C = correlation constant
Critical velocity changes as gas rate and tubing pressure shift over time. A fixed close-trigger threshold set six months ago does not account for any of that. The correlations also do not account well for horizontal undulations. They were derived for vertical flow, and the moment the wellbore deviates into a horizontal section with topographic variation, liquid pools in the low spots regardless of what the surface velocity calculation says. Tasq recalculates the threshold continuously against the actual time series, combining the physics prediction with what the SCADA data is actually showing.
Critical velocity is an indicator. Plunger drop time governs the rest of the cycle. The plunger has to physically fall from the lubricator to the bumper spring before the next cycle can begin, and that fall time is a function of plunger type, fluid level in the tubing, and tubing pressure. A standard Foss and Gaul drop-velocity model is the field workhorse: roughly 1,000 ft/min through dry gas, dropping to 150 to 200 ft/min once the plunger hits the liquid column. The inputs all require tweaking and refining.
L = tubing depth (ft)
Lliq = liquid column height (ft)
vgas = fall velocity through gas (~1,000 ft/min)
vliq = fall velocity through liquid (~150–200 ft/min)
The number this produces is a hard floor on close time. If the controller's close timer is shorter than tdrop, the well opens before the plunger has reached bottom and the cycle starts from a degraded state. Comparing the calculated drop time against actual arrival times surfaces three distinct conditions: a controller setpoint that is too aggressive, a plunger that is falling slower than expected because the liquid column has grown, or a mechanical issue where the plunger is stalling somewhere it should not.
For plunger wells specifically there is no usable VLP model short of CFD. Casing pressure is the practical analog for producing bottomhole pressure, and the detection logic on a plunger well has to be built around casing pressure trends rather than a computed VLP curve. This matters because misapplying gas-lift-style nodal analysis to a plunger well produces wrong recommendations.
The setpoint diagnosis only goes so far. A mushroomed out striking rod on a lubricator for a ball and sleeve plunger will cause intermittent plunger failures that look like a setpoint problem but are actually mechanical. The signature is similar: arrivals get inconsistent, cycle times drift, slugs come up light. Without the time series and the ability to compare expected behavior across thousands of analogous wells, that mechanical failure mode gets misclassified as a tuning problem, the engineer changes the close trigger, and the actual issue continues. The model has to know what the population behaves like before it can tell you what one well is doing wrong.
Setpoint optimization: gas lift
Gas lift optimization is not the act of finding an idealized curve intersection. It is a business decision constrained by compression. The rule of thumb is roughly 80 percent of the gas volume needed for maximum drawdown. The peak of the performance curve gives you the most barrels for that well, but the bottleneck is almost always compression availability across the pad and the gathering system. Operating right at the peak on every well leaves no headroom and starves the wells where the next incremental Mscf would have been more valuable.
The inflow side is described by Vogel for solution-gas-drive wells below the bubble point.
qmax = absolute open flow potential
Pwf = flowing bottomhole pressure
Pr = average reservoir pressure
The production curve is where the correlation library actually earns its keep. Standing's correlations on PVT properties feed the density and viscosity terms. Hagedorn-Brown handles the vertical multiphase flow profile through the tubing. The surface setpoint model has to account for gas lift valve set pressures changing as producing pressures and flowing temperatures drop with time in ways that the surface setpoint model needs to account for. A valve that has a 800 psig surface injection pressure at installation will not be at the same pressure two years later. The recommendation engine has to factor that drift in or it will keep suggesting injection-rate changes that the downhole valves will not honor.
Pad interactions
Before line pressure ever enters the picture, the wells on a pad are already interacting with each other. Casing pressure on one well influences the back side of the neighbor through shared annular communication paths. A well that kicks off after a shut-in pushes a gas slug into the common header and raises the local pressure every other well has to flow against. Pad-level compression cycling changes the suction pressure that every well sees within seconds. Plunger arrivals on one well can stack against a neighbor's tubing pressure if the gathering is undersized. These are first-order effects, and they happen continuously regardless of what the gathering system upstream is doing.
Line pressure sits on top of those interactions, not in place of them. When the gathering system tightens, a 50 PSI swing is not a single-well event. It propagates through the tubing of every well tied into that line and shifts each well's production curve in the same direction at the same time, on top of whatever pad-level interactions are already in play. Good optimization shields the well from these line pressure issues. The setpoint on a well that has been tuned against the live header pressure, with the neighbor interactions accounted for, holds its operating point through swings that would knock an untuned neighbor offline.
Pr = average reservoir pressure
Pwf = flowing bottomhole pressure
Rtotal = reservoir + tubing friction + wellhead backpressure
Beggs-Brill governs the multiphase pressure drop across the gathering pipelines that tie the pad into the broader system. Inclined runs, horizontal runs, the rolling topography between the wellhead and the central facility, all of it is described by the same correlation. When pipeline pressure drop changes, whether from a neighbor's slug, a compressor cycle, or a gathering-system event upstream, the math is the same: backpressure at the wellhead goes up, Pwf goes up, the IPR/VLP intersection shifts to the left, production drops. The effect is largest on the wells with the smallest margin between reservoir pressure and flowing bottomhole pressure, which is why the most unreliable pads see the biggest swing.
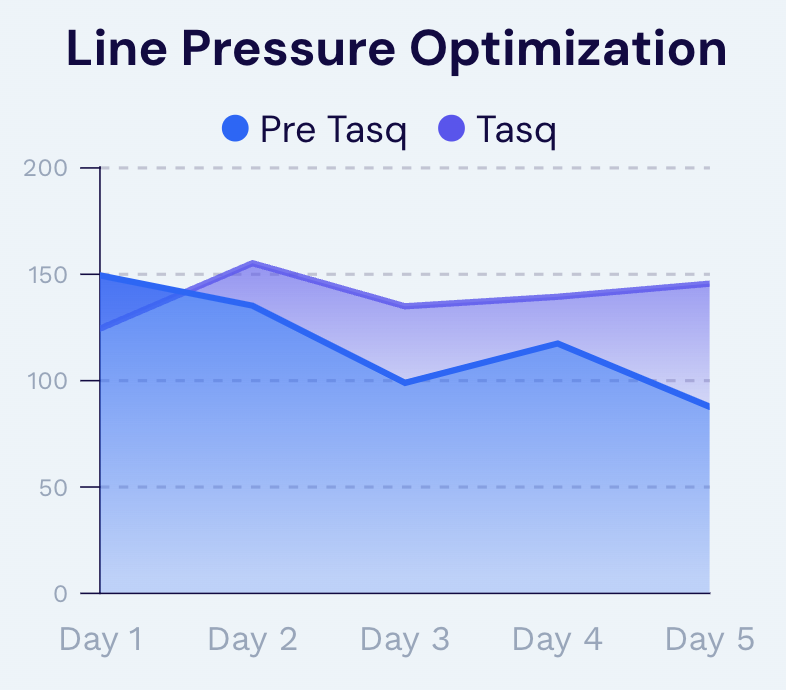
Why multiple models matter
Production is the intersection of inflow and the production curve. Setpoint changes move the production curve. Reservoir depletion moves the inflow curve. Line pressure events move the production curve for every well on the pad at once. Mechanical failures move neither curve and instead break the assumptions both curves are built on. A single monolithic model cannot disambiguate these. It will conflate a depletion-driven shift with a setpoint-driven shift, or it will flag a mechanical failure as a tuning issue.
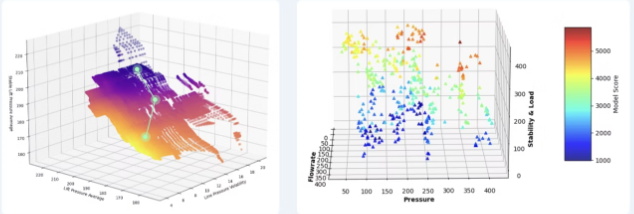
Tasq runs six model types in parallel. Each one is built around a specific question that maps to a specific lever or a specific side of the nodal picture. Some inform the inflow side, some inform the production curve side, some monitor the assumptions that both sides depend on, and some watch for the failure modes that exist outside the nodal framework entirely. The set is designed so that a recommendation surfaces only when multiple models agree on the cause.
The interactions matter as much as the individual models. A setpoint optimization recommendation that does not account for current line pressure will move the operating point in the wrong direction. A real-time alarm that does not consult the bulk and test prediction model will flag a well that is actually performing on plan. A build-your-own model that watches separator burner behavior will catch downtime that none of the production-side models would see because the cause is not a well-level event. The value comes from the network of models being coherent, not from any one of them being right in isolation.
Early detection
Threshold-based alarms only fire after a value crosses a static line. By that point the production drop has already accumulated and the deferment has already hit the daily report. The alternative is to model the expected relationship between signals and detect divergence from that expectation, well before any single signal breaches its own threshold.
On a producing well, casing pressure, tubing pressure, flowrate, and differential pressure across the choke or orifice have a physics-based relationship. When the well is healthy, those four signals move together in a predictable band. When the well is starting to load, the relationship breaks before any individual signal looks alarming on its own. Casing creeps up while tubing flattens. Flowrate oscillates while differential drops. None of those moves individually trips an alarm, but the joint pattern is the signature of liquid accumulation. It is checking whether actual gas velocity has dropped below the critical velocity threshold continuously, not at a single point in time.
The same approach extends to slower-moving failure modes. On paraffin buildup, the drivers are thermodynamic and operational. Wax appearance temperature, flowing temperature profile, flow velocity, chemical inhibitor program, and mechanical removal like plungers all set where and how fast restriction builds. What Tasq detects in the time series is the downstream effect: injection pressure gradually increasing as the effective tubing diameter shrinks from deposition. The detection window is 8 days. That is 8 days where you can schedule a treatment at your convenience versus reacting to a production drop that has already hit your daily report. Threshold monitoring on injection pressure alone would not catch this until the restriction was severe enough to register at the surface gauge, which is too late.
A recommendation is a hypothesis
Optimizing one part of the system is easy: pick a correlation, fire it on every well, surface every violation. Most of the output is not actionable, because a single correlation cannot tell whether a violation is a real opportunity or a downstream symptom of something it cannot see.
This is where the difference between physics-based, ML-based, and AI optimization actually matters, and it applies to every data type in operations, not just artificial lift. Physics-based optimization runs the correlations. It tells you what should happen given the inputs, whether the domain is plunger cycles, gas lift valves, compressor curves, separator levels, choke performance, or tank gauging. It is precise when the inputs are clean and silent when they are not. ML-based optimization runs the patterns. It tells you that something looks like a known signature in the time series, whether the signal is casing pressure, vibration, motor current, dump cycles, or flow rate. It generalizes across wells and equipment but cannot explain why a recommendation is what it is, which means an engineer cannot trust it without independent verification.
AI optimization combines both and makes the result explainable. The physics tells you what should happen. The ML tells you what is happening across the population of analogous assets. The AI layer reconciles the two, attaches the surrounding context, what was changed, what it was derived off of, which features crossed the threshold, and presents a recommendation that an engineer can interrogate. Ask why this well and not that one. Ask which signal drove the score. Ask what the model would do if line pressure dropped by 30 PSI. That conversation is the difference between a recommendation that gets actioned and one that gets ignored.
The second-order effect is iteration speed. When the model is explainable, the engineer can refine it directly. Add a feature, exclude a signal that turns out to be noisy on a specific lift type, raise the threshold for a population segment. Iteration time on building a new model drops from quarters to hours, and the value of each iteration shows up in the next cycle of recommendations rather than the next budget year.
The hard work is testing each recommendation against the surrounding context before surfacing it. Two wells with identical critical-velocity violations can warrant opposite responses. The physics is the same; the context is what makes a recommendation actionable. A point solution running one correlation cannot do that. A platform that runs the full library against a single connected data layer, with the explainability and iteration loop above, can.
Setpoint optimization results
The table below pulls observed setpoint optimization results from operator deployments. The numbers are not from a single well or a single month. They are the field-validated outcome of running the mechanisms described above continuously across a population.
| Deployment | Scope | Production result | Monthly value |
|---|---|---|---|
| Setpoint optimization, mixed lift | 45 wells | +221 BOE/d, +15% normalized oil post-Tasq | $380K/mo |
| Setpoint optimization, gas wells | 19 wells | 11% uplift, +410 Mscf/d, +56 BOPD | $180K/mo |
| Pad optimization | Pad-level | 11% production increase; 15% on GAPL, 10% on plungers | $100K/mo |
| Line pressure event response | Most unreliable pads | +23% production increase after detection and response | $110K/mo |
| Optimization model, Q4 2022 trial | 50 wells | 14% uplift | $50K/mo |
| Multi-mechanism, full deployment | 2,500 wells | 15% production uplift on optimized subset | $2M/mo |
| Scaled Deployment | Across deployments | 94% reduction in repetitive work; 68% setpoint, 32% equipment recommendation split; 90% model accuracy | $500K/mo |
The recommendation split (68% setpoint, 32% equipment) is the part of the table that ties back to the opening framing. A meaningful share of the value comes from correctly classifying when the problem is not a setpoint problem. A setpoint-only optimizer would mis-attribute that 32% and recommend tuning changes against mechanical signatures that need a field response instead.
The three examples below show the same pattern from three different angles. Each well was already producing. None of them were broken. Tasq AI optimization moved each one from good performance to better performance.
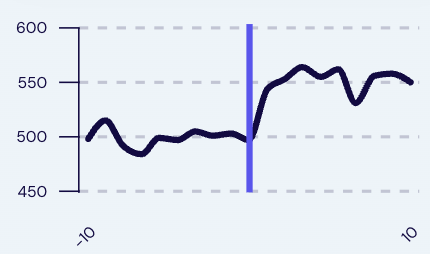
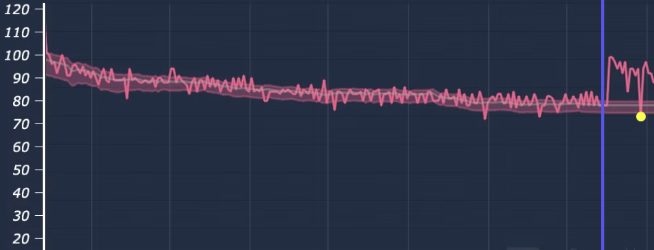
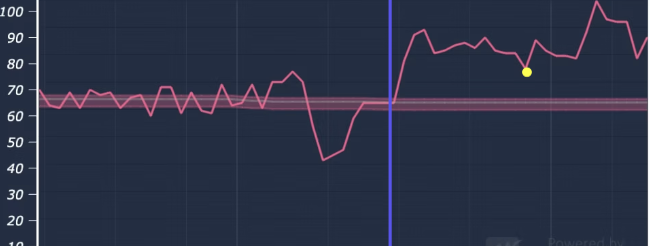
Summary
There is always room for optimization on a producing well. The setpoint can almost always move closer to optimal, the pad can almost always hold line pressure tighter, the early-detection window can almost always pull deferment forward into a scheduled response. The question is never whether the opportunity exists. It is whether the model can tell you where the opportunity actually lives, and whether the recommendation is grounded enough that a production engineer will act on it.
The mechanisms are not new. Foss and Gaul, Vogel, Hagedorn-Brown, Beggs-Brill, and the rest of the correlation library have been on the shelf for decades. The change is that they can now be evaluated continuously, per well, per cycle, against live SCADA, across thousands of wells, with enough context surrounding each evaluation to know which recommendations are worth surfacing. That last layer is where most of the work lives and where most of the value comes from.
The results table at the bottom of this article reflects that. Every row started from a well or a population that was already producing. AI optimization moved each of them from good performance to better performance, and it did so consistently enough that the numbers reproduce across operators, basins, and lift types.